1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
| from bs4 import BeautifulSoup
import requests
import pandas as pd
from fake_useragent import UserAgent
import os.path
import time
import pymysql
import multiprocessing
def get_content(url):
ua = UserAgent()
headers = {'user-agent': ua.random}
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
except Exception as e:
print('出现错误:',e)
def get_data(response):
all_data = []
soup = BeautifulSoup(response,'lxml')
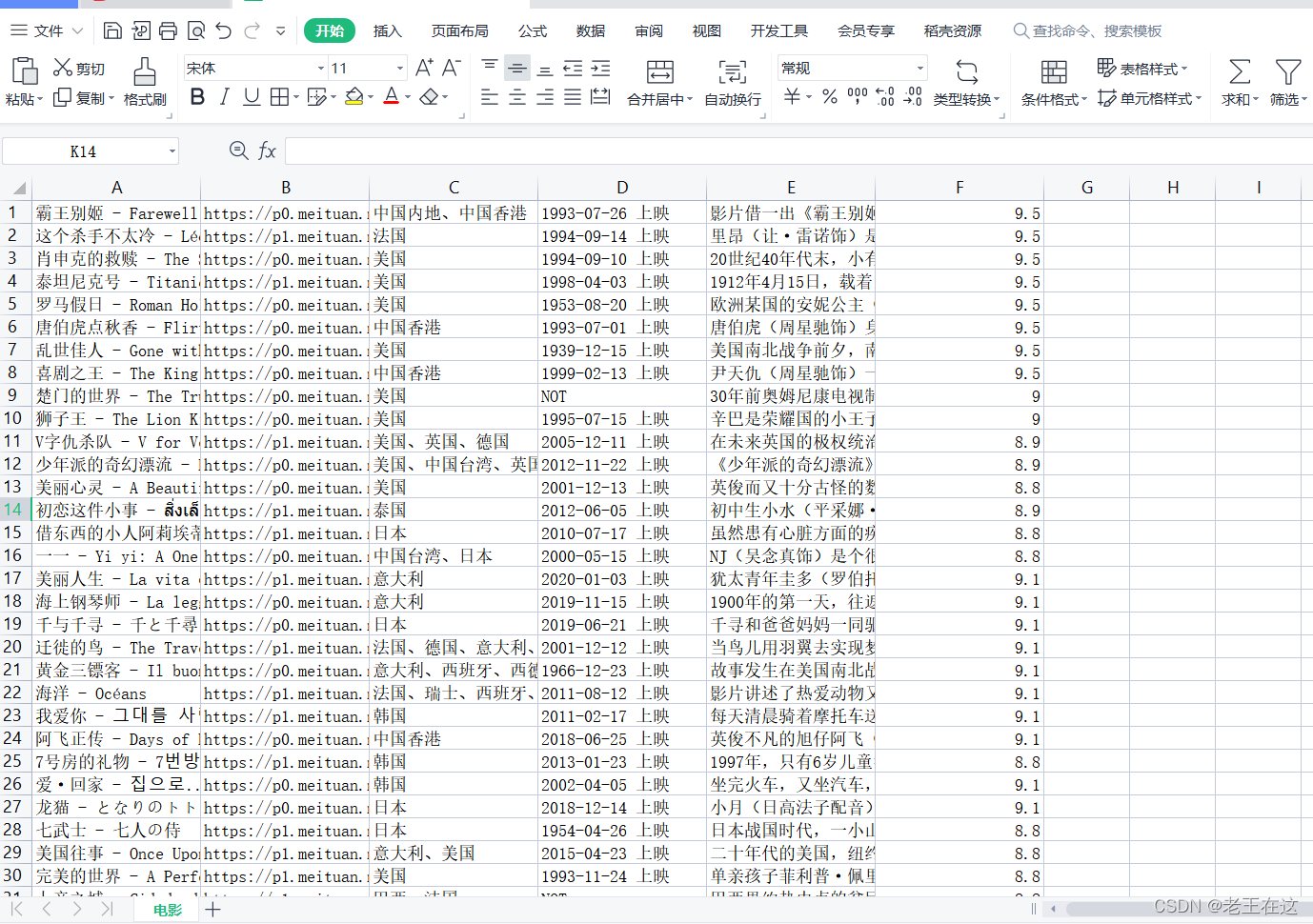
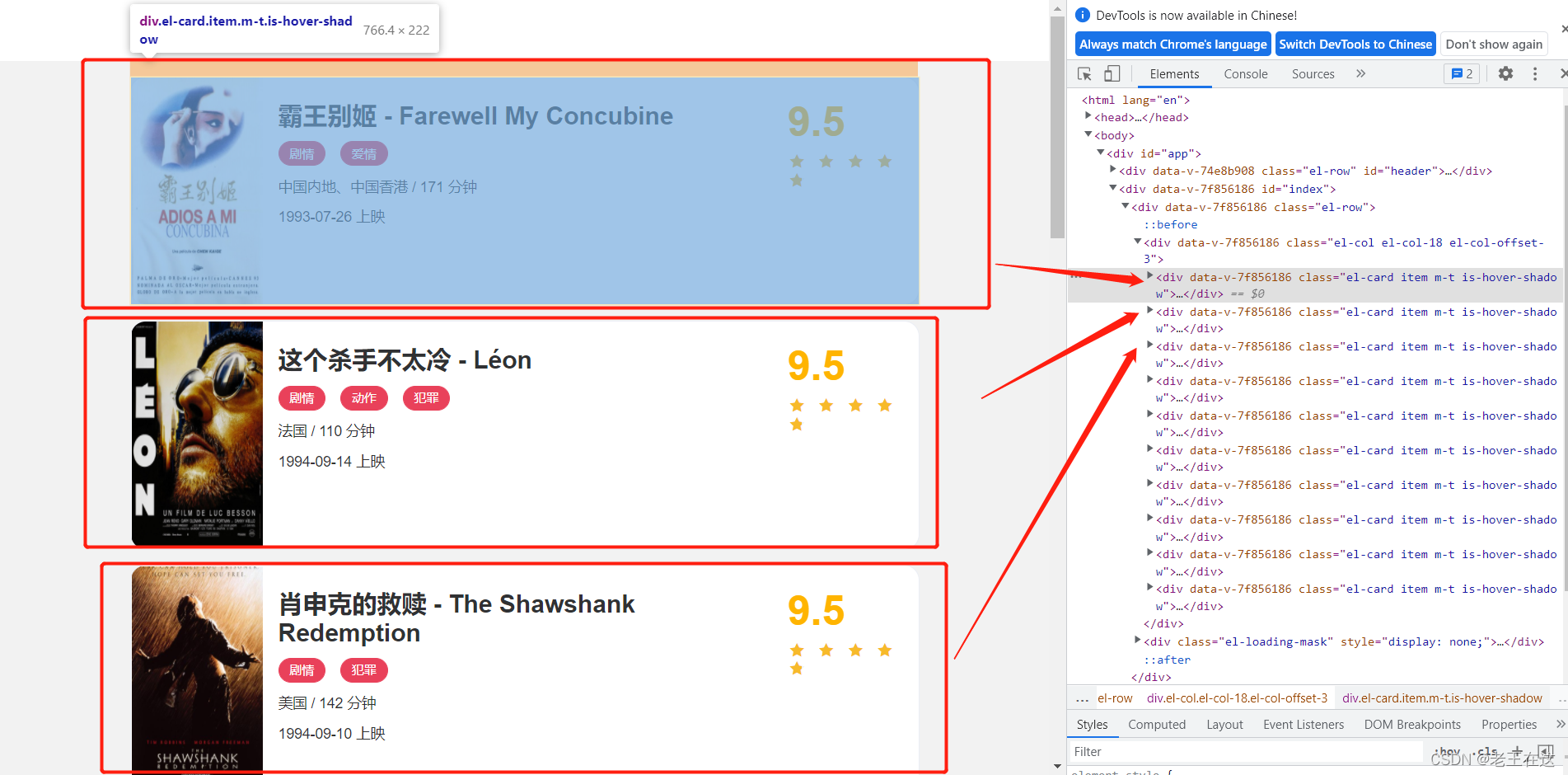
all_div = soup.find_all(class_="el-card item m-t is-hover-shadow")
for i in all_div:
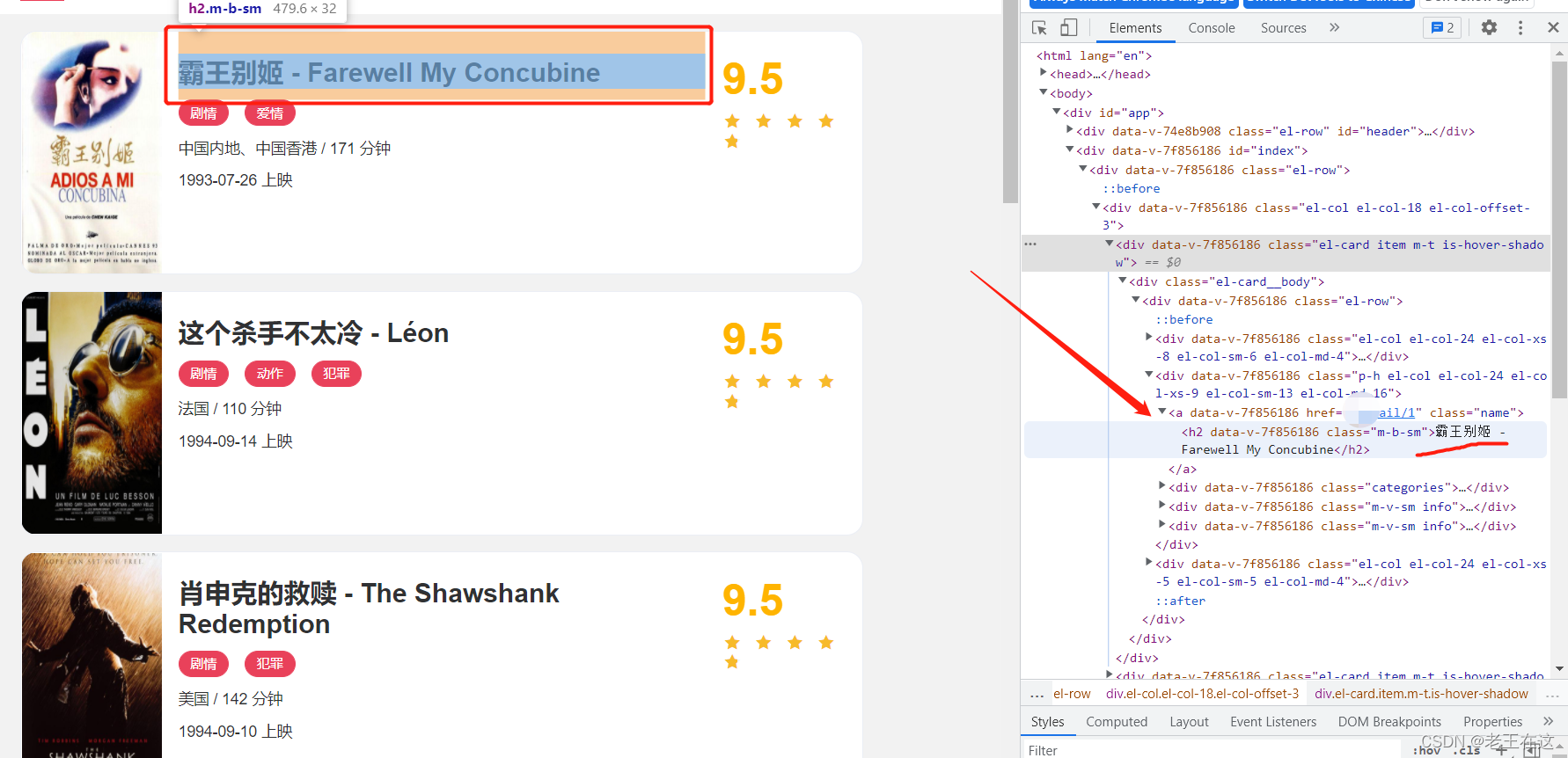
title = i.find(class_="m-b-sm").text
images = i.find('a').find('img').get('src')
details = 'https://ssr1.scrape.center' + i.find('a').get('href')
driver = requests.get(details).text
new_soup = BeautifulSoup(driver,'lxml')
lacation = new_soup.find_all(class_="m-v-sm info")[0].find('span').text
try:
time = new_soup.find_all(class_="m-v-sm info")[1].find('span').text
except:
time = 'NOT'
sort = new_soup.find(class_="drama").find('p').text.replace('\n','').replace(' ','')
scros = new_soup.find(class_="el-col el-col-24 el-col-xs-8 el-col-sm-4").find('p').text.replace(' ','').replace('\n','')
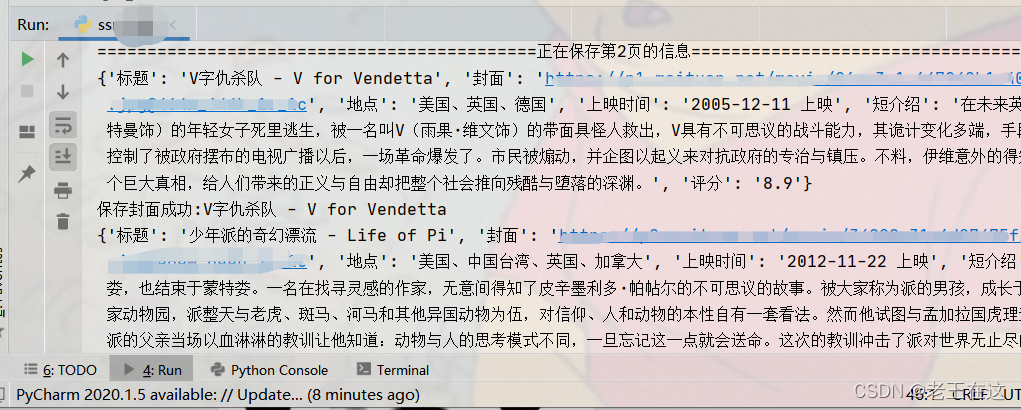
item = {
'标题': title,
'封面': images,
'地点': lacation,
'上映时间': time,
'短介绍': sort,
'评分': scros
}
print(item)
all_data.append(item)
save_images(title,images)
return all_data
def save_images(title,images):
if not os.path.exists('./ssrl/'):
os.mkdir('./ssrl/')
resp = requests.get(url=images).content
with open('./ssrl/' + title + '.jpg',mode='wb')as f:
f.write(resp)
print('保存封面成功:'+title)
def save_csv(all_data):
headers = ['标题','封面','地点','上映时间','短介绍','评分']
filt = pd.DataFrame(all_data)
filt.to_csv('ssrl.csv',mode='a+',header=False,encoding='utf-8',index=False)
return all_data
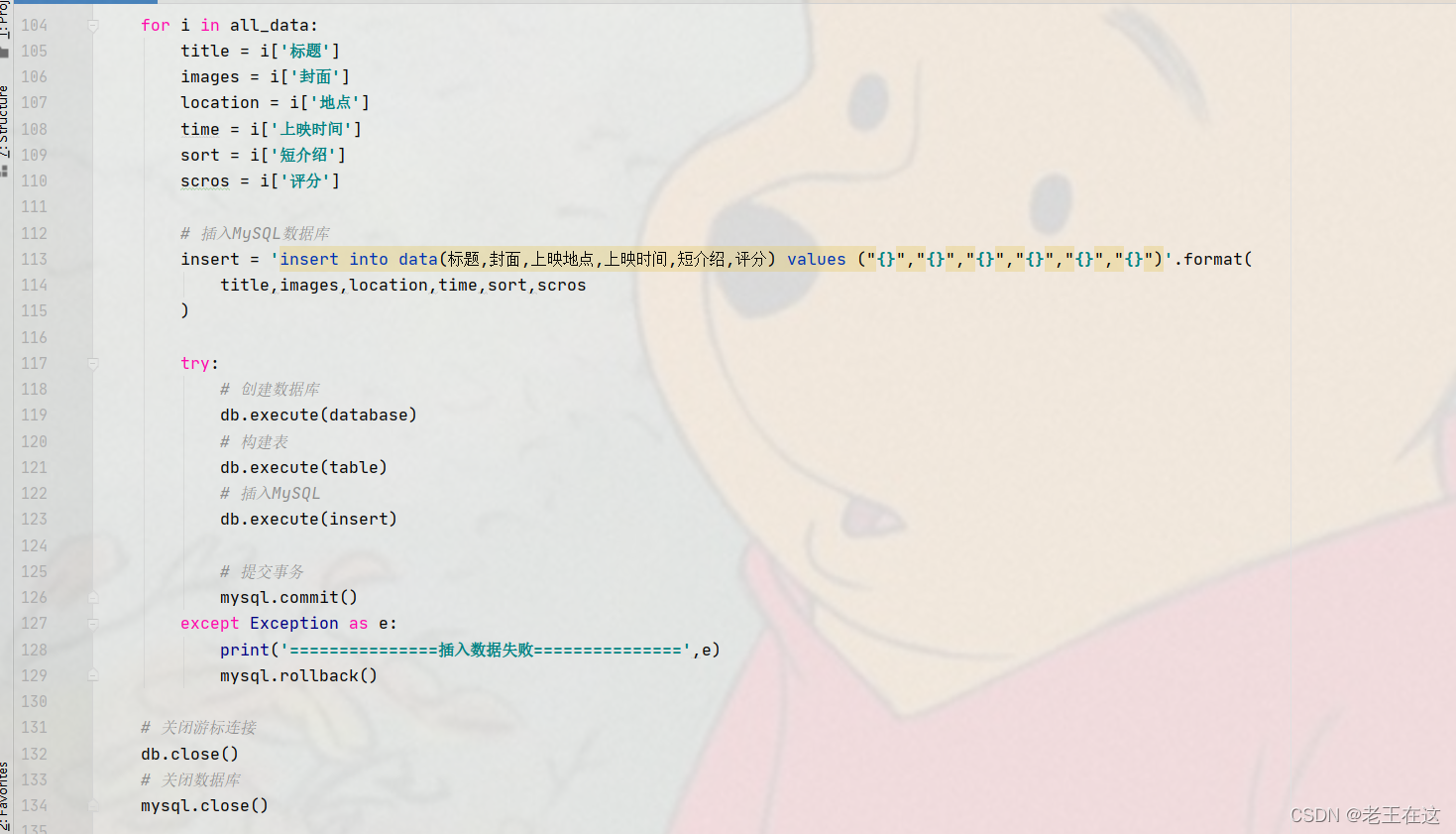
def sql_mysql(all_data):
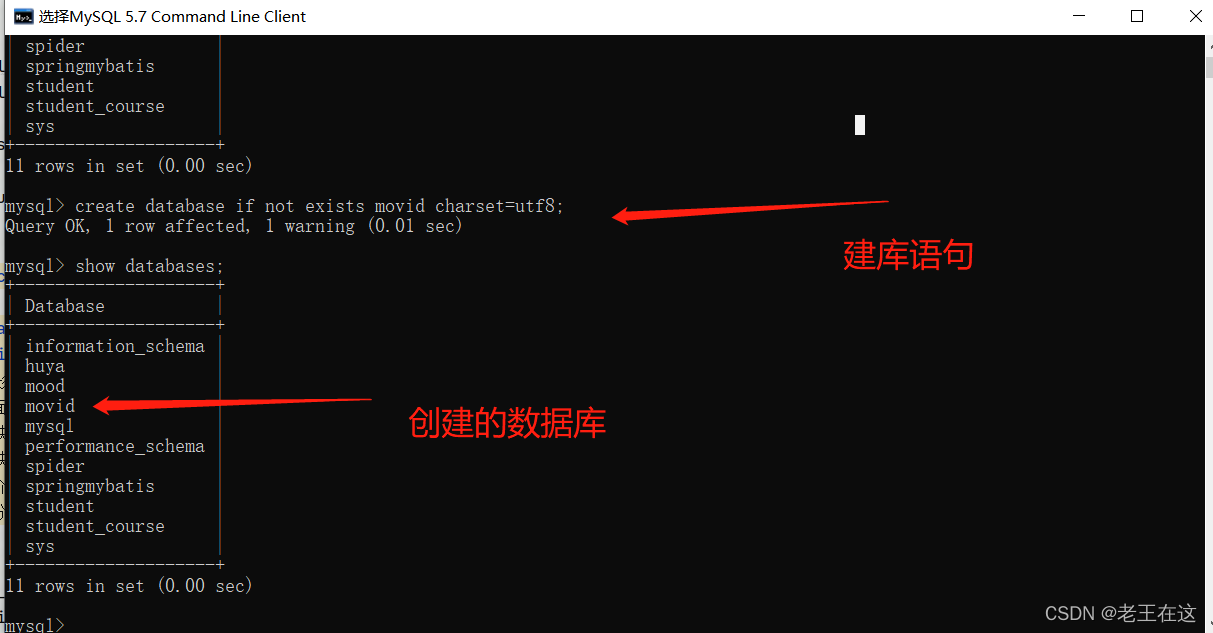
mysql = pymysql.connect(host='localhost',user='root',password='111111',port=3306,charset='utf8',database='movid')
db = mysql.cursor()
database = 'create database if not exists movid charset=utf8;'
table = 'create table if not exists data(' \
'id int not null primary key auto_increment' \
',标题 varchar(250)' \
',封面 varchar(250)' \
',上映地点 varchar(250)' \
',上映时间 varchar(250)' \
',短介绍 varchar(5000)' \
',评分 varchar(250)' \
');'
for i in all_data:
title = i['标题']
images = i['封面']
location = i['地点']
time = i['上映时间']
sort = i['短介绍']
scros = i['评分']
insert = 'insert into data(标题,封面,上映地点,上映时间,短介绍,评分) values ("{}","{}","{}","{}","{}","{}")'.format(
title,images,location,time,sort,scros
)
try:
db.execute(database)
db.execute(table)
db.execute(insert)
mysql.commit()
except Exception as e:
print('===============插入数据失败===============',e)
mysql.rollback()
db.close()
mysql.close()
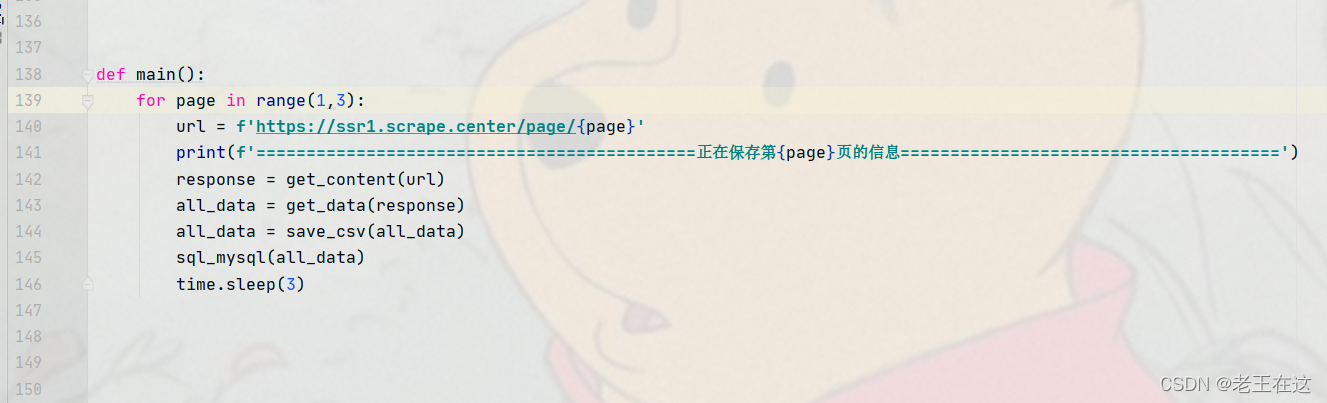
def main():
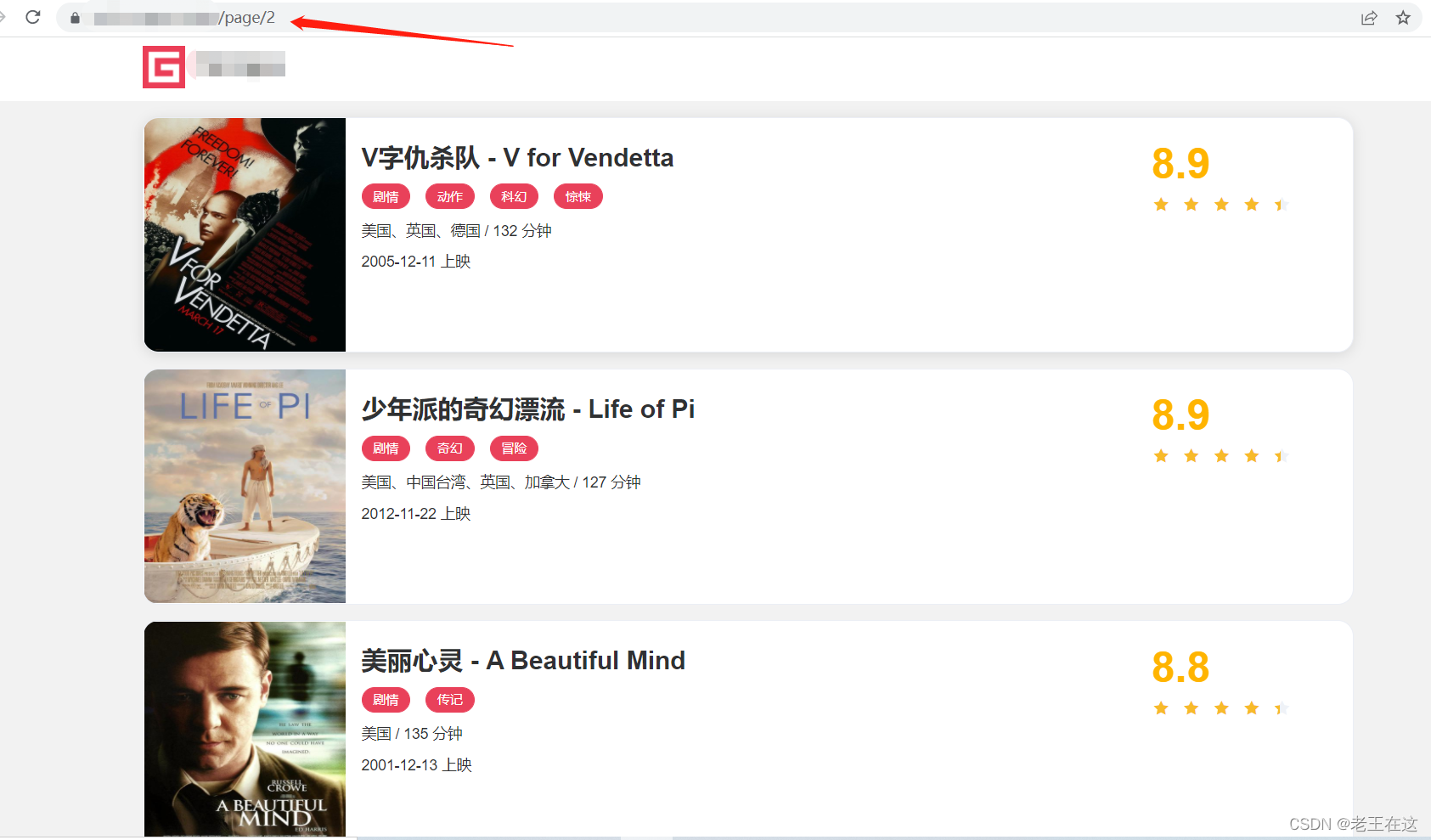
for page in range(1,3):
url = f'https://ssr1.scrape.center/page/{page}'
print(f'============================================正在保存第{page}页的信息======================================')
response = get_content(url)
all_data = get_data(response)
all_data = save_csv(all_data)
sql_mysql(all_data)
time.sleep(3)
if __name__ == '__main__':
muti = multiprocessing.Process(target=main)
muti.start()
|

 \
\